This post is also available in: Bosnian
Twitter gave no notice or explanation of the suspension, but Ana Toskic Cvetinovic, the executive director of Partners Serbia, had a hunch – that it was the result of a “coordinated attack”, probably other Twitter users submitting complaints about how the NGO was using its account.
“We tried for days to get at least some information from Twitter, like what could be the cause and how to solve the problem, but we haven’t received any answer,” Toskic Cvetinovic told BIRN. “After a month of silence, we saw that a new account was the only option.”
Twitter lifted the suspension in January, again without explanation. But Partners Serbia is far from alone among NGOs, media organisations and public figures in the Balkans who have had their social media accounts suspended without proper explanation or sometimes any explanation at all, according to BIRN monitoring of digital rights and freedom violations in the region.
Experts say the lack of transparency is a significant problem for those using social media as a vital channel of communication, not least because they are left in the dark as to what can be done to prevent such suspensions in the future.
But while organisations like Partners Serbia can face arbitrary suspension, half of the posts on Facebook and Twitter that are reported as hate speech, threatening violence or harassment in Bosnian, Serbian, Montenegrin or Macedonian remain online, according to the results of a BIRN survey, despite confirmation from the companies that the posts violated rules.
The investigation shows that the tools used by social media giants to protect their community guidelines are failing: posts and accounts that violate the rules often remain available even when breaches are acknowledged, while others that remain within those rules can be suspended without any clear reason.
Among BIRN’s findings are the following:
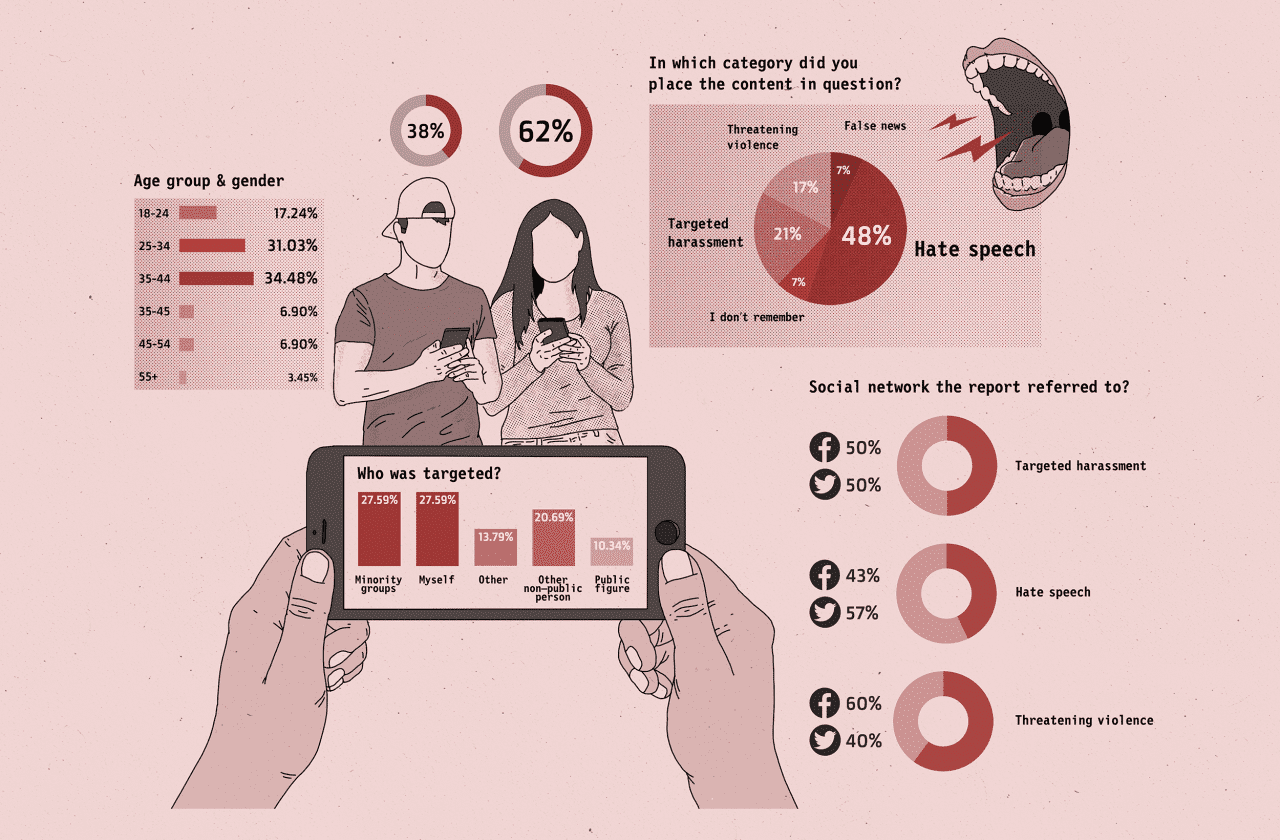
- Almost half of reports in Bosnian, Serbian, Montenegrin or Macedonian language to Facebook and Twitter are about hate speech
- One in two posts reported as hate speech, threatening violence or harassment in Bosnian, Serbian, Montenegrin or Macedonian language, remains online. When it comes to reports of threatening violence, the content was removed in 60 per cent of cases, and 50 per cent in cases of targeted harassment.
- Facebook and Twitter are using a hybrid model, a combination of artificial intelligence and human assessment in reviewing such reports, but declined to reveal how many of them are actually reviewed by a person proficient in Bosnian, Serbian, Montenegrin or Macedonian
- Both social networks adopt a “proactive approach”, which means they remove content or suspend accounts even without a report of suspicious conduct, but the criteria employed is unclear and transparency lacking.
- The survey showed that people were more ready to report content targeting them or minority groups.
Experts say the biggest problem could be the lack of transparency in how social media companies assess complaints.
The assessment itself is done in the first instance by an algorithm and, if necessary, a human gets involved later. But BIRN’s research shows that things get messy when it comes to the languages of the Balkans, precisely because of the specificity of language and context.
Distinguishing harsh criticism from defamation or radical political opinions from expressions of hatred and racism or incitement to violence require contextual and nuanced analysis.
Half of the posts containing hate speech remain online
 Graphic: BIRN/Igor Vujcic
Graphic: BIRN/Igor Vujcic
Facebook and Twitter are among the most popular social networks in the Balkans. The scope of their popularity is demonstrated in a 2020 report by DataReportal, an online platform that analyses how the world uses the Internet.
In January, there were around 3.7 million social media users in Serbia, 1.1 million in North Macedonia, 390,000 in Montenegro and 1.7 million in Bosnia and Herzegovina.
In each of the countries, Facebook is the most popular, with an estimated three million users in Serbia, 970,000 in North Macedonia, 300,000 in Montenegro and 1.4 million in Bosnia and Herzegovina.
Such numbers make Balkan countries attractive for advertising but also for the spread of political messages, opening the door to violations.
The debate over the benefits and the dangers of social media for 21st century society is well known.
In terms of violent content, besides the use of Artificial Intelligence, or AI, social media giants are trying to give users the means to react as well, chiefly by reporting violations to network administrators.
There are three kinds of filters – manual filtering by humans; automated filtering by algorithmic tools and hybrid filtering, performed by a combination of humans and automated tools.
In cases of uncertainty, posts or accounts are submitted to human review before decisions are taken, or after in the event a user complaints about automated removal.
“Today, we primarily rely on AI for the detection of violating content on Facebook and Instagram, and in some cases to take action on the content automatically as well,” a Facebook spokesperson told BIRN. “We utilize content reviewers for reviewing and labelling specific content, particularly when technology is less effective at making sense of context, intent or motivation.”
Twitter told BIRN that it is increasing the use of machine learning and automation to enforce the rules.
“Today, by using technology, more than 50 per cent of abusive content that’s enforced on our service is surfaced proactively for human review instead of relying on reports from people using Twitter,” said a company spokesperson.
“We have strong and dedicated teams of specialists who provide 24/7 global coverage in multiple different languages, and we are building more capacity to address increasingly complex issues.”
In order to check how effective those mechanisms are when it comes to content in Balkan languages, BIRN conducted a survey focusing on Facebook and Twitter reports and divided into three categories: violent threats (direct or indirect), harassment and hateful conduct.
The survey asked for the language of the disputed content, who was the target and who was the author, and whether or not the report was successful.
Over 48 per cent of respondents reported hate speech, some 20 per cent reported targeted harassment and some 17 per cent reported threatening violence.
The survey showed that people were more ready to report content targeting them or minority groups.
According to the survey, 43 per cent of content reported as hate speech remained online, while 57 per cent was removed. When it comes to reports of threatening violence, content was removed in 60 per cent of cases.
Roughly half of reports of targeted harassment resulted in removal.
Chloe Berthelemy, a policy advisor at European Digital Rights, EDRi, which works to promote digital rights, says the real-life consequences of neglect can be disastrous.
“For example, in cases of image-based sexual abuse [often wrongly called “revenge porn”], the majority of victims are women and they suffer from social exclusion as a result of these attacks,” Berthelemy said in a written response to BIRN. “For example, they can be discriminated against on the job market because recruiters search their online reputation.”
Content removal – censorship or corrective?
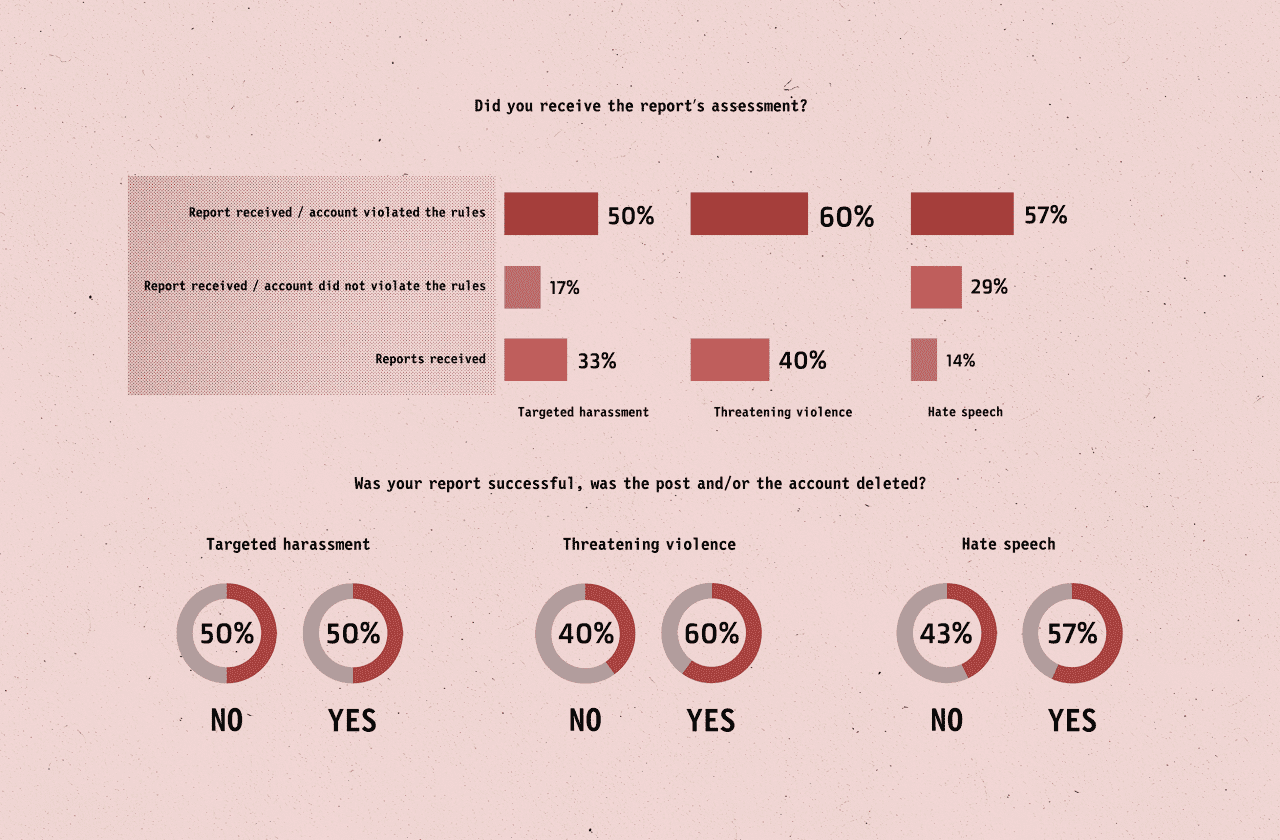 Graphic: BIRN/Igor Vujcic
Graphic: BIRN/Igor Vujcic
According to the responses to BIRN’s questionnaire, some 57 per cent of those who reported hate speech said they were notified that the reported post/account violated the rules.
On the other hand, some 28 per cent said they had received notification that the content they reported did not violate the rules, while 14 per cent received only confirmation that their report was filed.
In terms of reports of targeted harassment, half of people said they received confirmation that the content violated the rules; 16 per cent were told the content did not violate rules. A third of those who reported targeted harassment only received confirmation their report was received.
As for threatening violence, 40 per cent of people received confirmation that the reported post/account violated the rules while 60 per cent received only confirmation their complaint had been received.
One of the respondents told BIRN they had reported at least seven accounts for spreading hatred and violent content.
“I do not engage actively on such reports nor do I keep looking and searching them. However, when I do come across one of these hateful, genocide deniers and genocide supporters, it feels the right thing to do, to stop such content from going further,” the respondent said, speaking on condition of anonymity. “Maybe one of all the reported individuals stops and asks themselves what led to this and simply opens up discussions, with themselves or their circles.”
Although for those seven acounts Twitter confirmed they violate some of the rules, six of them are still available online.
BIRN methodology
BIRN conducted its questionnaire via the network’s tool for engaging citizens in reporting, developed in cooperation with the British Council.
The anonymous questionnaire had the aim of collecting information on what type of violations people reported, who was the target and how successful the report was. The questions were available in English, Macedonian, Albanian and Bosnian/Serbian/Montenegrin. BIRN focused on Facebook and Twitter given their popularity in the Balkans and the sensitivity of shared content, which is mostly textual and harder to assess compared to videos and photos.
Another issue that emerged is unclear criteria while reporting violations. Basic knowledge of English is also required.
Sanjana Hattotuwa, founder of Groundviews, Sri Lanka’s first citizen journalism website, and a researcher on new media literacy, web activism, digital security and online advocacy agreed that the in-app or web-based reporting process is confusing.
“Moreover, it is often in English even though the rest of the UI/UX [User Interface/User Experience] could be in the local language. Furthermore, the laborious selection of categories is, for a victim, not easy – especially under duress.”
Facebook told BIRN that the vast majority of reports are reviewed within 24 hours and that the company uses community reporting, human review and automation.
It refused, however, to give any specifics on those it employs to review content or reports in Balkan languages, saying “it isn’t accurate to only give the number of content reviewers”.
“That alone doesn’t reflect the number of people working on a content review for a particular country at any given time,” the spokesperson said.
Social networks often remove content themselves, in what they call a ‘proactive approach’.
According to data provided by Facebook, in the last quarter of 2017 their proactive detection rate was 23.6 per cent.
“This means that of the hate speech we removed, 23.6 per cent of it was found before a user reported it to us,” the spokesperson said. “The remaining majority of it was removed after a user reported it. Today we proactively detect about 95 per cent of hate speech content we remove.”
“Whether content is proactively detected or reported by users, we often use AI to take action on the straightforward cases and prioritise the more nuanced cases, where context needs to be considered, for our reviewers.”
There is no available data, however, when it comes to content in a specific language or country.
Facebook publishes a Community Standards Enforcement Report on a quarterly basis, but, according to the spokesperson, the company does not “disclose data regarding content moderation in specific countries.”
Whatever the tools, the results are sometimes highly questionable.
In May 2018, Facebook blocked for 24 hours the profile of Bosnian journalist Dragan Bursac after he posted a photo of a detention camp for Bosniaks in Serbia during the collapse of federal Yugoslavia in the 1990s.
Facebook determined that Bursac’s post had violated “community standards,” local media reported.
Bojan Kordalov, Skopje-based public relations and new media specialist, said that, “when evaluating efficiency in this area, it is important to emphasise that the traffic in the Internet space is very dense and is increasing every second, which unequivocally makes it a field where everyone needs to contribute”.
“This means that social media managements are undeniably responsible for meeting the standards and compliance with regulations within their platforms, but this does not absolve legislators, governments and institutions of responsibility in adapting to the needs of the new digital age, nor does it give anyone the right to redefine and narrow down the notion and the benefits that democracy brings.”
Lack of language sensibility

IIlustration. Photo: Unsplash/The Average Tech Guy
SHARE Foundation, a Belgrade-based NGO working on digital rights, said the question was crucial given the huge volume of content flowing through the likes of Facebook and Twitter in all languages.
“When it comes to relatively small language groups in absolute numbers of users, such as languages in the former Yugoslavia or even in the Balkans, there is simply no incentive or sufficient pressure from the public and political leaders to invest in human moderation,” SHARE told BIRN.
Berthelemy of EDRi said the Balkans were not a stand alone example, and that the content moderation practices and policies of Facebook and Twitter are “doomed to fail.”
“Many of these corporations operate on a massive scale, some of them serving up to a quarter of the world’s population with a single service,” Berthelemy told BIRN. “It is impossible for such monolithic architecture, and speech regulation process and policy to accommodate and satisfy the specific cultural and social needs of individuals and groups.”
The European Parliament has also stressed the importance of a combined assessment.
“The expressions of hatred can be conveyed in many ways, and the same words typically used to convey such expressions can also be used for different purposes,” according to a 2020 study – ‘The impact of algorithms for online content filtering or moderation’ – commissioned by the Parliament’s Policy Department for Citizens’ Rights and Constitutional Affairs.
“For instance, such words can be used for condemning violence, injustice or discrimination against the targeted groups, or just for describing their social circumstances. Thus, to identify hateful content in textual messages, an attempt must be made at grasping the meaning of such messages, using the resources provided by natural language processing.”
Hattotuwa said that, in general, “non-English language markets with non-Romanic (i.e. not English letter based) scripts are that much harder to design AI/ML solutions around”.
“And in many cases, these markets are out of sight and out of mind, unless the violence, abuse or platform harms are so significant they hit the New York Times front-page,” Hattotuwa told BIRN.
“Humans are necessary for evaluations, but as you know, there are serious emotional / PTSD issues related to the oversight of violent content, that companies like Facebook have been sued for (and lost, having to pay damages).”
Failing in non-English

Illustration. Photo: Unsplash/Ann Ann
Dragan Vujanovic of the Sarajevo-based NGO Vasa prava [Your Rights] criticised what he said was a “certain level of tolerance with regards to violations which support certain social narratives.”
“This is particularly evident in the inconsistent behavior of social media moderators where accounts with fairly innocuous comments are banned or suspended while other accounts, with overt abuse and clear negative social impact, are tolerated.”
For Chloe Berthelemy, trying to apply a uniform set of rules on the very diverse range of norms, values and opinions on all available topics that exist in the world is “meant to fail.”
Machine learning
As cited in the 2020 study commissioned by the European Parliament, Facebook has developed a machine learning approach called Whole Post Integrity Embeddings, WPIE, to deal with content violating Facebook guidelines.
The system addresses multimedia content by providing a holistic analysis of a post’s visual and textual content and related comments, across all dimensions of inappropriateness (violence, hate, nudity, drugs, etc.). The company claims that automated tools have improved the implementation of Facebook content guidelines. For instance, about 4.4 million items of drug sale content were removed in just the third quarter of 2019, 97.6 per cent of which were detected proactively.
When it comes to the ways in which social networks deal with suspicious content, Hattotuwa said that “context is key”.
While acknowledging advancements in the past two to three years, Hattotuwa said that, “No AI and ML [Machine Learning] I am aware of even in English language contexts can accurately identify the meaning behind an image.”
“With regards to content inciting hate, hurt and harm,” he said, “it is even more of a challenge.”
“For instance, where nudity is considered to be sensitive in the United States, other cultures take a more liberal approach,” she said.
The example of Myanmar, when Facebook effectively blocked an entire language by refusing all messages written in Jinghpaw, a language spoken by Myanmar’s ethnic Kachin and written with a Roman alphabet, shows the scale of the issue.
“The platform performs very poorly at detecting hate speech in non-English languages,” Berthelemy told BIRN.
The techniques used to filter content differ depending on the media analysed, according to the 2020 study for the European Parliament.
“A filter can work at different levels of complexity, spanning from simply comparing contents against a blacklist, to more sophisticated techniques employing complex AI techniques,” it said.
“In machine learning approaches, the system, rather than being provided with a logical definition of the criteria to be used to find and classify content (e.g., to determine what counts as hate speech, defamation, etc.) is provided with a vast set of data, from which it must learn on its own the criteria for making such a classification.”
Users of both Twitter and Facebook can appeal in the event their accounts are suspended or blocked.
“Unfortunately, the process lacks transparency, as the number of filed appeals is not mentioned in the transparency report, nor is the number of processed or reinstated accounts or tweets,” the study noted.
Between January and October 2020, Facebook restored some 50,000 items of content without an appeal and 613,000 after appeal.
According to the Twitter Transparency report, in the first six months of 2020, 12.4 million accounts were reported to the company, just over six million of which were reported for hateful conduct and some 5.1 million for “abuse/harassment”.
In the same period, Twitter suspended 925,744 accounts, of which 127,954 were flagged for hateful conduct and 72,139 for abuse/harassment. The company removed such content in a little over 1.9 million cases: 955,212 in the hateful conduct category and 609,253 in the abuse/harassment category.
Toskic Cvetinovic said the rules needed to be clearer and better communicated to users by “living people.”
“Often, the content removal doesn’t have a corrective function, but amounts to censorship,” she said.
Berthelemy said that, “because the dominant social media platforms reproduce the social systems of oppression, they are also often unsafe for many groups at the margins.”
“They are unable to understand the discriminatory and violent online behaviours, including certain forms of harassment and violent threats and therefore, cannot address the needs of victims,” Berthelemy told BIRN.
“Furthermore,” she said, “those social media networks are also advertisement companies. They rely on inflammatory content to generate profiling data and thus advertisement profits. There will be no effective, systematic response without addressing the business models of accumulating and trading personal data.”